DevOps / Sys Admin Q & A #10 : Trouble Shooting
What does performance mean to us?
To troubleshoot performance issues of our system, we need to understand the relationship between load, throughput, and response time.
- Load is where it all starts. It is the demand for work to be done (for example, 500 queries per second). Without it, we have no work and, therefore, no response time. This is also what causes performance to degrade. At some point, there is a greater demand for work than
the application's capacity of delivering, which is when bottlenecks occur.
- Throughput (for example, 1,000 requests per second) is the execution rate of the work being demanded. The relationship between load and throughput is predictable. As load increases, throughput will also increase until some resource gets saturated, after which throughput will get plateaued. When throughput plateaus, it's an indicator our application scales any more.
- Response time (msec) is the side effect of throughput. While throughput increase proportionately to load, response time will increase negligibly, but once the system reaches throughput plateau, response time will increase exponentially with the telltale "hockey stick" curve as queuing occurs.
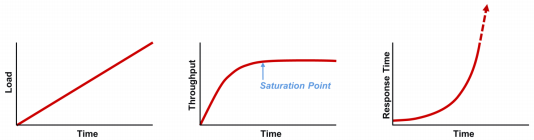
Source: reference 1
The relationship between load and throughput becomes increasingly important in complex multi-tier applications. When a throughput plateau occurs, it may be visible across the multiple tiers simultaneously as shown in the picture below:
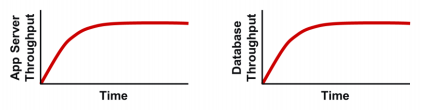
We could blame downstream items in situations like this, because poor performance downstream usually bubbles upstream. That could be a proper assessment for response time, however, it does not always apply to throughput.
By comparing throughput to load at each tier, we can identify what the root cause is. Here's one possible scenario corresponding to the throughput above, where the load scales linearly at each tier. In our case, since the load actually did increase continually at the database tier, we can safely identify that the bottleneck is indeed on the downstream database tier.
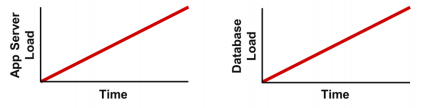
We may have another scenario where the app server load increases linearly, but does not propagate to the database tier as shown in the picture below:
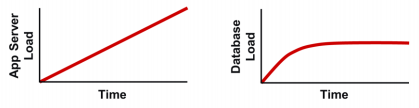
So, the bottleneck is not in database tier but actually in the application server, which is not passing the load down to the database server. Note that load is the demand for work, and at some point the database is not being asked for anything additional. Without additional load, we won't have additional throughput.
Note: this section is based on ref #1.
"A leak occurs whenever an application uses a resource and then doesn't give it back when it's done. Possible resources include memory, file handles, database connections, and many other things. Even resources like CPU and I/O can leak if the calling code encounters an unexpected condition that causes a loop it can't break out of, and then processing accumulates over time asmore instances of that code stack up."
Do we a have a leak?
Here are some signs that we most likely have a leak, or some leak-like behavior, in our application:- App gets progressively slower over time, requiring routine restarts to resolve.
- App gets progressively slower over time, but restarts don't help.
- App runs fine for a few days or weeks and then suddenly starts failing, requiring a restart.
- Can see some resource's utilization growing over time, requiring a restart to resolve the issue.
- Haven't made any changes to the app's code or environment, yet its behavior changes over time.
We can monitor the heap utilization (heap dump) of each app's object in real time and trend it historically:
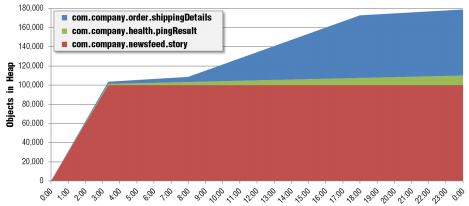
We can see the blue and green objects have some issues of leaking.
DevOps
DevOps / Sys Admin Q & A
Linux - system, cmds & shell
- Linux Tips - links, vmstats, rsync
- Linux Tips 2 - ctrl a, curl r, tail -f, umask
- Linux - bash I
- Linux - bash II
- Linux - Uncompressing 7z file
- Linux - sed I (substitution: sed 's///', sed -i)
- Linux - sed II (file spacing, numbering, text conversion and substitution)
- Linux - sed III (selective printing of certain lines, selective definition of certain lines)
- Linux - 7 File types : Regular, Directory, Block file, Character device file, Pipe file, Symbolic link file, and Socket file
- Linux shell programming - introduction
- Linux shell programming - variables and functions (readonly, unset, and functions)
- Linux shell programming - special shell variables
- Linux shell programming : arrays - three different ways of declaring arrays & looping with $*/$@
- Linux shell programming : operations on array
- Linux shell programming : variables & commands substitution
- Linux shell programming : metacharacters & quotes
- Linux shell programming : input/output redirection & here document
- Linux shell programming : loop control - for, while, break, and break n
- Linux shell programming : string
- Linux shell programming : for-loop
- Linux shell programming : if/elif/else/fi
- Linux shell programming : Test
- Managing User Account - useradd, usermod, and userdel
- Linux Secure Shell (SSH) I : key generation, private key and public key
- Linux Secure Shell (SSH) II : ssh-agent & scp
- Linux Secure Shell (SSH) III : SSH Tunnel as Proxy - Dynamic Port Forwarding (SOCKS Proxy)
- Linux Secure Shell (SSH) IV : Local port forwarding (outgoing ssh tunnel)
- Linux Secure Shell (SSH) V : Reverse SSH Tunnel (remote port forwarding / incoming ssh tunnel) /)
- Linux Processes and Signals
- Linux Drivers 1
- tcpdump
- Linux Debugging using gdb
- Embedded Systems Programming I - Introduction
- Embedded Systems Programming II - gcc ARM Toolchain and Simple Code on Ubuntu/Fedora
- LXC (Linux Container) Install and Run
- Linux IPTables
- Hadoop - 1. Setting up on Ubuntu for Single-Node Cluster
- Hadoop - 2. Runing on Ubuntu for Single-Node Cluster
- ownCloud 7 install
- Ubuntu 14.04 guest on Mac OSX host using VirtualBox I
- Ubuntu 14.04 guest on Mac OSX host using VirtualBox II
- Windows 8 guest on Mac OSX host using VirtualBox I
- Ubuntu Package Management System (apt-get vs dpkg)
- RPM Packaging
- How to Make a Self-Signed SSL Certificate
- Linux Q & A
- DevOps / Sys Admin questions
Ph.D. / Golden Gate Ave, San Francisco / Seoul National Univ / Carnegie Mellon / UC Berkeley / DevOps / Deep Learning / Visualization