Apache Hadoop (CDH 5) - Tutorial I (OverView)
This tutorial will show how to use hadoop with CDH 5 cluster on EC2.
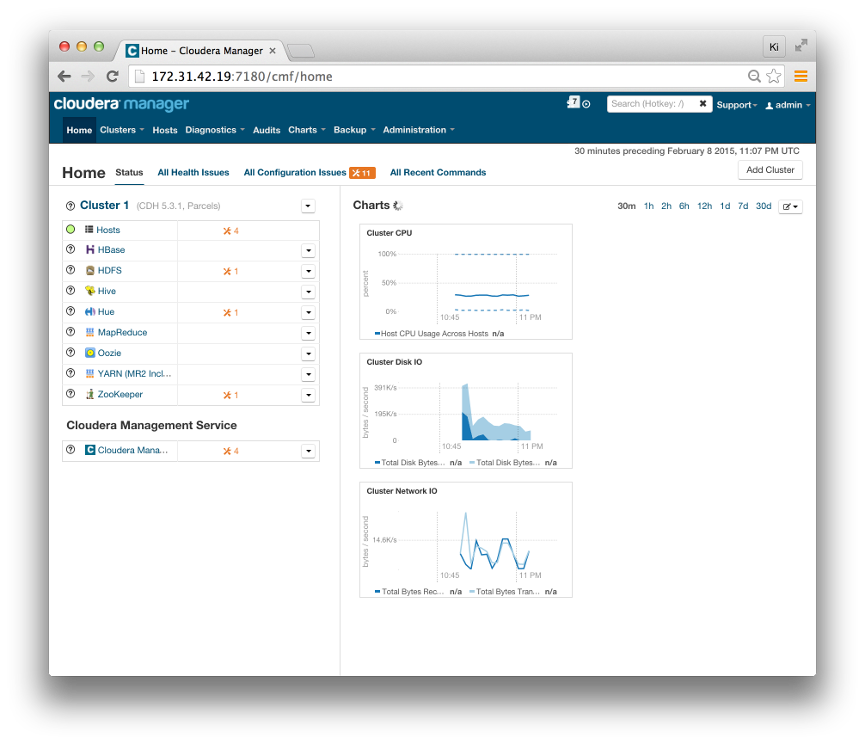
We have 4 EC2 instances, one for Name node and three for Data nodes.
To see how to setup CDH5 on EC2, please visit Apache Hadoop Install - CDH5.
Hadoop MapReduce is a software framework for writing applications that process vast amounts of data. The data processing is done in parallel on large clusters. The clusters consist of thousands of nodes of commodity hardware in a reliable, fault-tolerant manner.
A MapReduce job usually splits the input dataset into independent chunks. Then, they are processed by the map tasks in parallel. The Hadoop MapReduce framework sorts the outputs of the maps. Then, they are used as input to the reduce tasks. Typically both the input and the output of the job are stored in a distributed filesystem.
Typically, the MapReduce framework and the Hadoop Distributed File System (HDFS) are running on the same set of nodes. In other words, the compute nodes and the storage nodes are the same. Putting them into the same node allows the framework to effectively schedule tasks on the nodes where data is already present. This way we can get very high aggregate bandwidth across the cluster.
The MapReduce runtime framework consists of a single JobTracker and one TaskTracker per cluster node. The JobTracker is responsible for scheduling the jobs' component tasks on the TaskTracker nodes, monitoring the tasks, and re-executing failed tasks. The TaskTracker nodes execute the tasks as directed by the JobTracker:
The applications specify the input and output locations and supply map and reduce functions. The functions implements appropriate interfaces and/or abstract classes. These locations and functions and other job parameters comprise the job configuration. Then, the Hadoop job client submits the job (such as an executable) and configuration to the JobTracker. The JobTracker, then distributes the software and configuration to the TaskTracker nodes. The JobTracker also responsible for scheduling tasks and monitoring them, and providing status and diagnostic information to the job client.
The Hadoop framework is implemented in Java. So, we may want to develop MapReduce applications in Java or any JVM-based language or use one of the following interfaces:
- Hadoop Streaming - a utility that allows you to create and run jobs with any executables (for example, shell utilities) as the mapper and/or the reducer.
- Hadoop Pipes - a SWIG-compatible (not based on JNI) C++ API to implement MapReduce applications.
In this tutorial, we'll use org.apache.hadoop.mapred Java API. Note that there is a newer Java API, org.apache.hadoop.mapreduce.
Big Data & Hadoop Tutorials
Hadoop 2.6 - Installing on Ubuntu 14.04 (Single-Node Cluster)
Hadoop 2.6.5 - Installing on Ubuntu 16.04 (Single-Node Cluster)
Hadoop - Running MapReduce Job
Hadoop - Ecosystem
CDH5.3 Install on four EC2 instances (1 Name node and 3 Datanodes) using Cloudera Manager 5
CDH5 APIs
QuickStart VMs for CDH 5.3
QuickStart VMs for CDH 5.3 II - Testing with wordcount
QuickStart VMs for CDH 5.3 II - Hive DB query
Scheduled start and stop CDH services
CDH 5.8 Install with QuickStarts Docker
Zookeeper & Kafka Install
Zookeeper & Kafka - single node single broker
Zookeeper & Kafka - Single node and multiple brokers
OLTP vs OLAP
Apache Hadoop Tutorial I with CDH - Overview
Apache Hadoop Tutorial II with CDH - MapReduce Word Count
Apache Hadoop Tutorial III with CDH - MapReduce Word Count 2
Apache Hadoop (CDH 5) Hive Introduction
CDH5 - Hive Upgrade to 1.3 to from 1.2
Apache Hive 2.1.0 install on Ubuntu 16.04
Apache Hadoop : HBase in Pseudo-Distributed mode
Apache Hadoop : Creating HBase table with HBase shell and HUE
Apache Hadoop : Hue 3.11 install on Ubuntu 16.04
Apache Hadoop : Creating HBase table with Java API
Apache HBase : Map, Persistent, Sparse, Sorted, Distributed and Multidimensional
Apache Hadoop - Flume with CDH5: a single-node Flume deployment (telnet example)
Apache Hadoop (CDH 5) Flume with VirtualBox : syslog example via NettyAvroRpcClient
List of Apache Hadoop hdfs commands
Apache Hadoop : Creating Wordcount Java Project with Eclipse Part 1
Apache Hadoop : Creating Wordcount Java Project with Eclipse Part 2
Apache Hadoop : Creating Card Java Project with Eclipse using Cloudera VM UnoExample for CDH5 - local run
Apache Hadoop : Creating Wordcount Maven Project with Eclipse
Wordcount MapReduce with Oozie workflow with Hue browser - CDH 5.3 Hadoop cluster using VirtualBox and QuickStart VM
Spark 1.2 using VirtualBox and QuickStart VM - wordcount
Spark Programming Model : Resilient Distributed Dataset (RDD) with CDH
Apache Spark 1.2 with PySpark (Spark Python API) Wordcount using CDH5
Apache Spark 1.2 Streaming
Apache Spark 2.0.2 with PySpark (Spark Python API) Shell
Apache Spark 2.0.2 tutorial with PySpark : RDD
Apache Spark 2.0.0 tutorial with PySpark : Analyzing Neuroimaging Data with Thunder
Apache Spark Streaming with Kafka and Cassandra
Apache Drill with ZooKeeper - Install on Ubuntu 16.04
Apache Drill - Query File System, JSON, and Parquet
Apache Drill - HBase query
Apache Drill - Hive query
Apache Drill - MongoDB query
Ph.D. / Golden Gate Ave, San Francisco / Seoul National Univ / Carnegie Mellon / UC Berkeley / DevOps / Deep Learning / Visualization
Big Data & Hadoop Tutorials
Hadoop 2.6 - Installing on Ubuntu 14.04 (Single-Node Cluster)
Hadoop 2.6.5 - Installing on Ubuntu 16.04 (Single-Node Cluster)
Hadoop - Running MapReduce Job
Hadoop - Ecosystem
CDH5.3 Install on four EC2 instances (1 Name node and 3 Datanodes) using Cloudera Manager 5
CDH5 APIs
QuickStart VMs for CDH 5.3
QuickStart VMs for CDH 5.3 II - Testing with wordcount
QuickStart VMs for CDH 5.3 II - Hive DB query
Scheduled start and stop CDH services
CDH 5.8 Install with QuickStarts Docker
Zookeeper & Kafka Install
Zookeeper & Kafka - single node single broker
Zookeeper & Kafka - Single node and multiple brokers
OLTP vs OLAP
Apache Hadoop Tutorial I with CDH - Overview
Apache Hadoop Tutorial II with CDH - MapReduce Word Count
Apache Hadoop Tutorial III with CDH - MapReduce Word Count 2
Apache Hadoop (CDH 5) Hive Introduction
CDH5 - Hive Upgrade to 1.3 to from 1.2
Apache Hive 2.1.0 install on Ubuntu 16.04
Apache HBase in Pseudo-Distributed mode
Creating HBase table with HBase shell and HUE
Apache Hadoop : Hue 3.11 install on Ubuntu 16.04
Creating HBase table with Java API
HBase - Map, Persistent, Sparse, Sorted, Distributed and Multidimensional
Flume with CDH5: a single-node Flume deployment (telnet example)
Apache Hadoop (CDH 5) Flume with VirtualBox : syslog example via NettyAvroRpcClient
List of Apache Hadoop hdfs commands
Apache Hadoop : Creating Wordcount Java Project with Eclipse Part 1
Apache Hadoop : Creating Wordcount Java Project with Eclipse Part 2
Apache Hadoop : Creating Card Java Project with Eclipse using Cloudera VM UnoExample for CDH5 - local run
Apache Hadoop : Creating Wordcount Maven Project with Eclipse
Wordcount MapReduce with Oozie workflow with Hue browser - CDH 5.3 Hadoop cluster using VirtualBox and QuickStart VM
Spark 1.2 using VirtualBox and QuickStart VM - wordcount
Spark Programming Model : Resilient Distributed Dataset (RDD) with CDH
Apache Spark 2.0.2 with PySpark (Spark Python API) Shell
Apache Spark 2.0.2 tutorial with PySpark : RDD
Apache Spark 2.0.0 tutorial with PySpark : Analyzing Neuroimaging Data with Thunder
Apache Spark Streaming with Kafka and Cassandra
Apache Spark 1.2 with PySpark (Spark Python API) Wordcount using CDH5
Apache Spark 1.2 Streaming
Apache Drill with ZooKeeper install on Ubuntu 16.04 - Embedded & Distributed
Apache Drill - Query File System, JSON, and Parquet
Apache Drill - HBase query
Apache Drill - Hive query
Apache Drill - MongoDB query
Elasticsearch search engine, Logstash, and Kibana
Elasticsearch, search engine
Logstash with Elasticsearch
Logstash, Elasticsearch, and Kibana 4
Elasticsearch with Redis broker and Logstash Shipper and Indexer
Samples of ELK architecture
Elasticsearch indexing performance
DevOps
Phases of Continuous Integration
Software development methodology
Introduction to DevOps
Samples of Continuous Integration (CI) / Continuous Delivery (CD) - Use cases
Artifact repository and repository management
Linux - General, shell programming, processes & signals ...
RabbitMQ...
MariaDB
New Relic APM with NodeJS : simple agent setup on AWS instance
Nagios on CentOS 7 with Nagios Remote Plugin Executor (NRPE)
Nagios - The industry standard in IT infrastructure monitoring on Ubuntu
Zabbix 3 install on Ubuntu 14.04 & adding hosts / items / graphs
Datadog - Monitoring with PagerDuty/HipChat and APM
Install and Configure Mesos Cluster
Cassandra on a Single-Node Cluster
Container Orchestration : Docker Swarm vs Kubernetes vs Apache Mesos
OpenStack install on Ubuntu 16.04 server - DevStack
AWS EC2 Container Service (ECS) & EC2 Container Registry (ECR) | Docker Registry
CI/CD with CircleCI - Heroku deploy
Introduction to Terraform with AWS elb & nginx
Docker & Kubernetes
Kubernetes I - Running Kubernetes Locally via Minikube
Kubernetes II - kops on AWS
Kubernetes III - kubeadm on AWS
AWS : EKS (Elastic Container Service for Kubernetes)
CI/CD Github actions
CI/CD Gitlab
DevOps / Sys Admin Q & A
(1A) - Linux Commands
(1B) - Linux Commands
(2) - Networks
(2B) - Networks
(3) - Linux Systems
(4) - Scripting (Ruby/Shell)
(5) - Configuration Management
(6) - AWS VPC setup (public/private subnets with NAT)
(6B) - AWS VPC Peering
(7) - Web server
(8) - Database
(9) - Linux System / Application Monitoring, Performance Tuning, Profiling Methods & Tools
(10) - Trouble Shooting: Load, Throughput, Response time and Leaks
(11) - SSH key pairs, SSL Certificate, and SSL Handshake
(12) - Why is the database slow?
(13) - Is my web site down?
(14) - Is my server down?
(15) - Why is the server sluggish?
(16A) - Serving multiple domains using Virtual Hosts - Apache
(16B) - Serving multiple domains using server block - Nginx
(16C) - Reverse proxy servers and load balancers - Nginx
(17) - Linux startup process
(18) - phpMyAdmin with Nginx virtual host as a subdomain
(19) - How to SSH login without password?
(20) - Log Rotation
(21) - Monitoring Metrics
(22) - lsof
(23) - Wireshark introduction
(24) - User account management
(25) - Domain Name System (DNS)
(26) - NGINX SSL/TLS, Caching, and Session
(27) - Troubleshooting 5xx server errors
(28) - Linux Systemd: journalctl
(29) - Linux Systemd: FirewallD
(30) - Linux: SELinux
(31) - Linux: Samba
(0) - Linux Sys Admin's Day to Day tasks
AWS (Amazon Web Services)
AWS : EKS (Elastic Container Service for Kubernetes)
AWS : Creating a snapshot (cloning an image)
AWS : Attaching Amazon EBS volume to an instance
AWS : Adding swap space to an attached volume via mkswap and swapon
AWS : Creating an EC2 instance and attaching Amazon EBS volume to the instance using Python boto module with User data
AWS : Creating an instance to a new region by copying an AMI
AWS : S3 (Simple Storage Service) 1
AWS : S3 (Simple Storage Service) 2 - Creating and Deleting a Bucket
AWS : S3 (Simple Storage Service) 3 - Bucket Versioning
AWS : S3 (Simple Storage Service) 4 - Uploading a large file
AWS : S3 (Simple Storage Service) 5 - Uploading folders/files recursively
AWS : S3 (Simple Storage Service) 6 - Bucket Policy for File/Folder View/Download
AWS : S3 (Simple Storage Service) 7 - How to Copy or Move Objects from one region to another
AWS : S3 (Simple Storage Service) 8 - Archiving S3 Data to Glacier
AWS : Creating a CloudFront distribution with an Amazon S3 origin
AWS : Creating VPC with CloudFormation
WAF (Web Application Firewall) with preconfigured CloudFormation template and Web ACL for CloudFront distribution
AWS : CloudWatch & Logs with Lambda Function / S3
AWS : Lambda Serverless Computing with EC2, CloudWatch Alarm, SNS
AWS : Lambda and SNS - cross account
AWS : CLI (Command Line Interface)
AWS : CLI (ECS with ALB & autoscaling)
AWS : ECS with cloudformation and json task definition
AWS : AWS Application Load Balancer (ALB) and ECS with Flask app
AWS : Load Balancing with HAProxy (High Availability Proxy)
AWS : VirtualBox on EC2
AWS : NTP setup on EC2
AWS: jq with AWS
AWS : AWS & OpenSSL : Creating / Installing a Server SSL Certificate
AWS : OpenVPN Access Server 2 Install
AWS : VPC (Virtual Private Cloud) 1 - netmask, subnets, default gateway, and CIDR
AWS : VPC (Virtual Private Cloud) 2 - VPC Wizard
AWS : VPC (Virtual Private Cloud) 3 - VPC Wizard with NAT
AWS : DevOps / Sys Admin Q & A (VI) - AWS VPC setup (public/private subnets with NAT)
AWS : OpenVPN Protocols : PPTP, L2TP/IPsec, and OpenVPN
AWS : Autoscaling group (ASG)
AWS : Setting up Autoscaling Alarms and Notifications via CLI and Cloudformation
AWS : Adding a SSH User Account on Linux Instance
AWS : Windows Servers - Remote Desktop Connections using RDP
AWS : Scheduled stopping and starting an instance - python & cron
AWS : Detecting stopped instance and sending an alert email using Mandrill smtp
AWS : Elastic Beanstalk with NodeJS
AWS : Elastic Beanstalk Inplace/Rolling Blue/Green Deploy
AWS : Identity and Access Management (IAM) Roles for Amazon EC2
AWS : Identity and Access Management (IAM) Policies, sts AssumeRole, and delegate access across AWS accounts
AWS : Identity and Access Management (IAM) sts assume role via aws cli2
AWS : Creating IAM Roles and associating them with EC2 Instances in CloudFormation
AWS Identity and Access Management (IAM) Roles, SSO(Single Sign On), SAML(Security Assertion Markup Language), IdP(identity provider), STS(Security Token Service), and ADFS(Active Directory Federation Services)
AWS : Amazon Route 53
AWS : Amazon Route 53 - DNS (Domain Name Server) setup
AWS : Amazon Route 53 - subdomain setup and virtual host on Nginx
AWS Amazon Route 53 : Private Hosted Zone
AWS : SNS (Simple Notification Service) example with ELB and CloudWatch
AWS : Lambda with AWS CloudTrail
AWS : SQS (Simple Queue Service) with NodeJS and AWS SDK
AWS : Redshift data warehouse
AWS : CloudFormation - templates, change sets, and CLI
AWS : CloudFormation Bootstrap UserData/Metadata
AWS : CloudFormation - Creating an ASG with rolling update
AWS : Cloudformation Cross-stack reference
AWS : OpsWorks
AWS : Network Load Balancer (NLB) with Autoscaling group (ASG)
AWS CodeDeploy : Deploy an Application from GitHub
AWS EC2 Container Service (ECS)
AWS EC2 Container Service (ECS) II
AWS Hello World Lambda Function
AWS Lambda Function Q & A
AWS Node.js Lambda Function & API Gateway
AWS API Gateway endpoint invoking Lambda function
AWS API Gateway invoking Lambda function with Terraform
AWS API Gateway invoking Lambda function with Terraform - Lambda Container
Amazon Kinesis Streams
Kinesis Data Firehose with Lambda and ElasticSearch
Amazon DynamoDB
Amazon DynamoDB with Lambda and CloudWatch
Loading DynamoDB stream to AWS Elasticsearch service with Lambda
Amazon ML (Machine Learning)
Simple Systems Manager (SSM)
AWS : RDS Connecting to a DB Instance Running the SQL Server Database Engine
AWS : RDS Importing and Exporting SQL Server Data
AWS : RDS PostgreSQL & pgAdmin III
AWS : RDS PostgreSQL 2 - Creating/Deleting a Table
AWS : MySQL Replication : Master-slave
AWS : MySQL backup & restore
AWS RDS : Cross-Region Read Replicas for MySQL and Snapshots for PostgreSQL
AWS : Restoring Postgres on EC2 instance from S3 backup
AWS : Q & A
AWS : Security
AWS : Security groups vs. network ACLs
AWS : Scaling-Up
AWS : Networking
AWS : Single Sign-on (SSO) with Okta
AWS : JIT (Just-in-Time) with Okta
Docker & K8s
Docker install on Amazon Linux AMI
Docker install on EC2 Ubuntu 14.04
Docker container vs Virtual Machine
Docker install on Ubuntu 14.04
Docker Hello World Application
Nginx image - share/copy files, Dockerfile
Working with Docker images : brief introduction
Docker image and container via docker commands (search, pull, run, ps, restart, attach, and rm)
More on docker run command (docker run -it, docker run --rm, etc.)
Docker Networks - Bridge Driver Network
Docker Persistent Storage
File sharing between host and container (docker run -d -p -v)
Linking containers and volume for datastore
Dockerfile - Build Docker images automatically I - FROM, MAINTAINER, and build context
Dockerfile - Build Docker images automatically II - revisiting FROM, MAINTAINER, build context, and caching
Dockerfile - Build Docker images automatically III - RUN
Dockerfile - Build Docker images automatically IV - CMD
Dockerfile - Build Docker images automatically V - WORKDIR, ENV, ADD, and ENTRYPOINT
Docker - Apache Tomcat
Docker - NodeJS
Docker - NodeJS with hostname
Docker Compose - NodeJS with MongoDB
Docker - Prometheus and Grafana with Docker-compose
Docker - StatsD/Graphite/Grafana
Docker - Deploying a Java EE JBoss/WildFly Application on AWS Elastic Beanstalk Using Docker Containers
Docker : NodeJS with GCP Kubernetes Engine
Docker : Jenkins Multibranch Pipeline with Jenkinsfile and Github
Docker : Jenkins Master and Slave
Docker - ELK : ElasticSearch, Logstash, and Kibana
Docker - ELK 7.6 : Elasticsearch on Centos 7 Docker - ELK 7.6 : Filebeat on Centos 7
Docker - ELK 7.6 : Logstash on Centos 7
Docker - ELK 7.6 : Kibana on Centos 7 Part 1
Docker - ELK 7.6 : Kibana on Centos 7 Part 2
Docker - ELK 7.6 : Elastic Stack with Docker Compose
Docker - Deploy Elastic Cloud on Kubernetes (ECK) via Elasticsearch operator on minikube
Docker - Deploy Elastic Stack via Helm on minikube
Docker Compose - A gentle introduction with WordPress
Docker Compose - MySQL
MEAN Stack app on Docker containers : micro services
Docker Compose - Hashicorp's Vault and Consul Part A (install vault, unsealing, static secrets, and policies)
Docker Compose - Hashicorp's Vault and Consul Part B (EaaS, dynamic secrets, leases, and revocation)
Docker Compose - Hashicorp's Vault and Consul Part C (Consul)
Docker Compose with two containers - Flask REST API service container and an Apache server container
Docker compose : Nginx reverse proxy with multiple containers
Docker compose : Nginx reverse proxy with multiple containers
Docker & Kubernetes : Envoy - Getting started
Docker & Kubernetes : Envoy - Front Proxy
Docker & Kubernetes : Ambassador - Envoy API Gateway on Kubernetes
Docker Packer
Docker Cheat Sheet
Docker Q & A
Kubernetes Q & A - Part I
Kubernetes Q & A - Part II
Docker - Run a React app in a docker
Docker - Run a React app in a docker II (snapshot app with nginx)
Docker - NodeJS and MySQL app with React in a docker
Docker - Step by Step NodeJS and MySQL app with React - I
Installing LAMP via puppet on Docker
Docker install via Puppet
Nginx Docker install via Ansible
Apache Hadoop CDH 5.8 Install with QuickStarts Docker
Docker - Deploying Flask app to ECS
Docker Compose - Deploying WordPress to AWS
Docker - WordPress Deploy to ECS with Docker-Compose (ECS-CLI EC2 type)
Docker - ECS Fargate
Docker - AWS ECS service discovery with Flask and Redis
Docker & Kubernetes: minikube version: v1.31.2, 2023
Docker & Kubernetes 1 : minikube
Docker & Kubernetes 2 : minikube Django with Postgres - persistent volume
Docker & Kubernetes 3 : minikube Django with Redis and Celery
Docker & Kubernetes 4 : Django with RDS via AWS Kops
Docker & Kubernetes : Kops on AWS
Docker & Kubernetes : Ingress controller on AWS with Kops
Docker & Kubernetes : HashiCorp's Vault and Consul on minikube
Docker & Kubernetes : HashiCorp's Vault and Consul - Auto-unseal using Transit Secrets Engine
Docker & Kubernetes : Persistent Volumes & Persistent Volumes Claims - hostPath and annotations
Docker & Kubernetes : Persistent Volumes - Dynamic volume provisioning
Docker & Kubernetes : DaemonSet
Docker & Kubernetes : Secrets
Docker & Kubernetes : kubectl command
Docker & Kubernetes : Assign a Kubernetes Pod to a particular node in a Kubernetes cluster
Docker & Kubernetes : Configure a Pod to Use a ConfigMap
AWS : EKS (Elastic Container Service for Kubernetes)
Docker & Kubernetes : Run a React app in a minikube
Docker & Kubernetes : Minikube install on AWS EC2
Docker & Kubernetes : Cassandra with a StatefulSet
Docker & Kubernetes : Terraform and AWS EKS
Docker & Kubernetes : Pods and Service definitions
Docker & Kubernetes : Headless service and discovering pods
Docker & Kubernetes : Service IP and the Service Type
Docker & Kubernetes : Kubernetes DNS with Pods and Services
Docker & Kubernetes - Scaling and Updating application
Docker & Kubernetes : Horizontal pod autoscaler on minikubes
Docker & Kubernetes : NodePort vs LoadBalancer vs Ingress
Docker & Kubernetes : Load Testing with Locust on GCP Kubernetes
Docker & Kubernetes : From a monolithic app to micro services on GCP Kubernetes
Docker & Kubernetes : Rolling updates
Docker & Kubernetes : Deployments to GKE (Rolling update, Canary and Blue-green deployments)
Docker & Kubernetes : Slack Chat Bot with NodeJS on GCP Kubernetes
Docker & Kubernetes : Continuous Delivery with Jenkins Multibranch Pipeline for Dev, Canary, and Production Environments on GCP Kubernetes
Docker & Kubernetes - MongoDB with StatefulSets on GCP Kubernetes Engine
Docker & Kubernetes : Nginx Ingress Controller on minikube
Docker & Kubernetes : Setting up Ingress with NGINX Controller on Minikube (Mac)
Docker & Kubernetes : Nginx Ingress Controller for Dashboard service on Minikube
Docker & Kubernetes : Nginx Ingress Controller on GCP Kubernetes
Docker & Kubernetes : Kubernetes Ingress with AWS ALB Ingress Controller in EKS
Docker & Kubernetes : MongoDB / MongoExpress on Minikube
Docker & Kubernetes : Setting up a private cluster on GCP Kubernetes
Docker & Kubernetes : Kubernetes Namespaces (default, kube-public, kube-system) and switching namespaces (kubens)
Docker & Kubernetes : StatefulSets on minikube
Docker & Kubernetes : StatefulSets on minikube
Docker & Kubernetes : RBAC
Docker & Kubernetes Service Account, RBAC, and IAM
Docker & Kubernetes - Kubernetes Service Account, RBAC, IAM with EKS ALB, Part 1
Docker & Kubernetes : Helm Chart
Docker & Kubernetes : My first Helm deploy
Docker & Kubernetes : Readiness and Liveness Probes
Docker & Kubernetes : Helm chart repository with Github pages
Docker & Kubernetes : Deploying WordPress and MariaDB with Ingress to Minikube using Helm Chart
Docker & Kubernetes : Deploying WordPress and MariaDB to AWS using Helm 2 Chart
Docker & Kubernetes : Deploying WordPress and MariaDB to AWS using Helm 3 Chart
Docker & Kubernetes : Helm Chart for Node/Express and MySQL with Ingress
Docker & Kubernetes : Docker_Helm_Chart_Node_Expess_MySQL_Ingress.php
Docker & Kubernetes: Deploy Prometheus and Grafana using Helm and Prometheus Operator - Monitoring Kubernetes node resources out of the box
Docker & Kubernetes : Deploy Prometheus and Grafana using kube-prometheus-stack Helm Chart
Docker & Kubernetes : Istio (service mesh) sidecar proxy on GCP Kubernetes
Docker & Kubernetes : Istio on EKS
Docker & Kubernetes : Istio on Minikube with AWS EC2 for Bookinfo Application
Docker & Kubernetes : Deploying .NET Core app to Kubernetes Engine and configuring its traffic managed by Istio (Part I)
Docker & Kubernetes : Deploying .NET Core app to Kubernetes Engine and configuring its traffic managed by Istio (Part II - Prometheus, Grafana, pin a service, split traffic, and inject faults)
Docker & Kubernetes : Helm Package Manager with MySQL on GCP Kubernetes Engine
Docker & Kubernetes : Deploying Memcached on Kubernetes Engine
Docker & Kubernetes : EKS Control Plane (API server) Metrics with Prometheus
Docker & Kubernetes : Spinnaker on EKS with Halyard
Docker & Kubernetes : Continuous Delivery Pipelines with Spinnaker and Kubernetes Engine
Docker & Kubernetes: Multi-node Local Kubernetes cluster - Kubeadm-dind(docker-in-docker)
Docker & Kubernetes: Multi-node Local Kubernetes cluster - Kubeadm-kind(k8s-in-docker)
Docker & Kubernetes : nodeSelector, nodeAffinity, taints/tolerations, pod affinity and anti-affinity - Assigning Pods to Nodes
Docker & Kubernetes : Jenkins-X on EKS
Docker & Kubernetes : ArgoCD App of Apps with Heml on Kubernetes
Docker & Kubernetes : ArgoCD on Kubernetes cluster
Docker & Kubernetes : GitOps with ArgoCD for Continuous Delivery to Kubernetes clusters (minikube) - guestbook
Terraform
Introduction to Terraform with AWS elb & nginx
Terraform Tutorial - terraform format(tf) and interpolation(variables)
Terraform Tutorial - user_data
Terraform Tutorial - variables
Terraform 12 Tutorial - Loops with count, for_each, and for
Terraform Tutorial - creating multiple instances (count, list type and element() function)
Terraform Tutorial - State (terraform.tfstate) & terraform import
Terraform Tutorial - Output variables
Terraform Tutorial - Destroy
Terraform Tutorial - Modules
Terraform Tutorial - Creating AWS S3 bucket / SQS queue resources and notifying bucket event to queue
Terraform Tutorial - AWS ASG and Modules
Terraform Tutorial - VPC, Subnets, RouteTable, ELB, Security Group, and Apache server I
Terraform Tutorial - VPC, Subnets, RouteTable, ELB, Security Group, and Apache server II
Terraform Tutorial - Docker nginx container with ALB and dynamic autoscaling
Terraform Tutorial - AWS ECS using Fargate : Part I
Hashicorp Vault
HashiCorp Vault Agent
HashiCorp Vault and Consul on AWS with Terraform
Ansible with Terraform
AWS IAM user, group, role, and policies - part 1
AWS IAM user, group, role, and policies - part 2
Delegate Access Across AWS Accounts Using IAM Roles
AWS KMS
terraform import & terraformer import
Terraform commands cheat sheet
Terraform Cloud
Terraform 14
Creating Private TLS Certs
Ansible 2.0
What is Ansible?
Quick Preview - Setting up web servers with Nginx, configure environments, and deploy an App
SSH connection & running commands
Ansible: Playbook for Tomcat 9 on Ubuntu 18.04 systemd with AWS
Modules
Playbooks
Handlers
Roles
Playbook for LAMP HAProxy
Installing Nginx on a Docker container
AWS : Creating an ec2 instance & adding keys to authorized_keys
AWS : Auto Scaling via AMI
AWS : creating an ELB & registers an EC2 instance from the ELB
Deploying Wordpress micro-services with Docker containers on Vagrant box via Ansible
Setting up Apache web server
Deploying a Go app to Minikube
Ansible with Terraform
Jenkins
Install
Configuration - Manage Jenkins - security setup
Adding job and build
Scheduling jobs
Managing_plugins
Git/GitHub plugins, SSH keys configuration, and Fork/Clone
JDK & Maven setup
Build configuration for GitHub Java application with Maven
Build Action for GitHub Java application with Maven - Console Output, Updating Maven
Commit to changes to GitHub & new test results - Build Failure
Commit to changes to GitHub & new test results - Successful Build
Adding code coverage and metrics
Jenkins on EC2 - creating an EC2 account, ssh to EC2, and install Apache server
Jenkins on EC2 - setting up Jenkins account, plugins, and Configure System (JAVA_HOME, MAVEN_HOME, notification email)
Jenkins on EC2 - Creating a Maven project
Jenkins on EC2 - Configuring GitHub Hook and Notification service to Jenkins server for any changes to the repository
Jenkins on EC2 - Line Coverage with JaCoCo plugin
Setting up Master and Slave nodes
Jenkins Build Pipeline & Dependency Graph Plugins
Jenkins Build Flow Plugin
Pipeline Jenkinsfile with Classic / Blue Ocean
Jenkins Setting up Slave nodes on AWS
Jenkins Q & A
Puppet
Puppet with Amazon AWS I - Puppet accounts
Puppet with Amazon AWS II (ssh & puppetmaster/puppet install)
Puppet with Amazon AWS III - Puppet running Hello World
Puppet Code Basics - Terminology
Puppet with Amazon AWS on CentOS 7 (I) - Master setup on EC2
Puppet with Amazon AWS on CentOS 7 (II) - Configuring a Puppet Master Server with Passenger and Apache
Puppet master /agent ubuntu 14.04 install on EC2 nodes
Puppet master post install tasks - master's names and certificates setup,
Puppet agent post install tasks - configure agent, hostnames, and sign request
EC2 Puppet master/agent basic tasks - main manifest with a file resource/module and immediate execution on an agent node
Setting up puppet master and agent with simple scripts on EC2 / remote install from desktop
EC2 Puppet - Install lamp with a manifest ('puppet apply')
EC2 Puppet - Install lamp with a module
Puppet variable scope
Puppet packages, services, and files
Puppet packages, services, and files II with nginx Puppet templates
Puppet creating and managing user accounts with SSH access
Puppet Locking user accounts & deploying sudoers file
Puppet exec resource
Puppet classes and modules
Puppet Forge modules
Puppet Express
Puppet Express 2
Puppet 4 : Changes
Puppet --configprint
Puppet with Docker
Puppet 6.0.2 install on Ubuntu 18.04
Chef
What is Chef?
Chef install on Ubuntu 14.04 - Local Workstation via omnibus installer
Setting up Hosted Chef server
VirtualBox via Vagrant with Chef client provision
Creating and using cookbooks on a VirtualBox node
Chef server install on Ubuntu 14.04
Chef workstation setup on EC2 Ubuntu 14.04
Chef Client Node - Knife Bootstrapping a node on EC2 ubuntu 14.04
Vagrant
VirtualBox & Vagrant install on Ubuntu 14.04
Creating a VirtualBox using Vagrant
Provisioning
Networking - Port Forwarding
Vagrant Share
Vagrant Rebuild & Teardown
Vagrant & Ansible
Redis In-Memory Database
Redis vs Memcached
Redis 3.0.1 Install
Setting up multiple server instances on a Linux host
Redis with Python
ELK : Elasticsearch with Redis broker and Logstash Shipper and Indexer
Git/GitHub Tutorial
One page express tutorial for GIT and GitHub
Installation
add/status/log
commit and diff
git commit --amend
Deleting and Renaming files
Undoing Things : File Checkout & Unstaging
Reverting commit
Soft Reset - (git reset --soft <SHA key>)
Mixed Reset - Default
Hard Reset - (git reset --hard <SHA key>)
Creating & switching Branches
Fast-forward merge
Rebase & Three-way merge
Merge conflicts with a simple example
GitHub Account and SSH
Uploading to GitHub
GUI
Branching & Merging
Merging conflicts
GIT on Ubuntu and OS X - Focused on Branching
Setting up a remote repository / pushing local project and cloning the remote repo
Fork vs Clone, Origin vs Upstream
Git/GitHub Terminologies
Git/GitHub via SourceTree I : Commit & Push
Git/GitHub via SourceTree II : Branching & Merging
Git/GitHub via SourceTree III : Git Work Flow
Git/GitHub via SourceTree IV : Git Reset
Git Cheat sheet - quick command reference
Subversion
Subversion Install On Ubuntu 14.04Subversion creating and accessing I
Subversion creating and accessing II
Powershell 4 Tutorial
Powersehll : Introduction
Powersehll : Help System
Powersehll : Running commands
Powersehll : Providers
Powersehll : Pipeline
Powersehll : Objects
Powershell : Remote Control
Windows Management Instrumentation (WMI)
How to Enable Multiple RDP Sessions in Windows 2012 Server
How to install and configure FTP server on IIS 8 in Windows 2012 Server
How to Run Exe as a Service on Windows 2012 Server
SQL Inner, Left, Right, and Outer Joins
DevOps
Phases of Continuous Integration
Software development methodology
Introduction to DevOps
Samples of Continuous Integration (CI) / Continuous Delivery (CD) - Use cases
Artifact repository and repository management
Linux - General, shell programming, processes & signals ...
RabbitMQ...
MariaDB
New Relic APM with NodeJS : simple agent setup on AWS instance
Nagios on CentOS 7 with Nagios Remote Plugin Executor (NRPE)
Nagios - The industry standard in IT infrastructure monitoring on Ubuntu
Zabbix 3 install on Ubuntu 14.04 & adding hosts / items / graphs
Datadog - Monitoring with PagerDuty/HipChat and APM
Install and Configure Mesos Cluster
Cassandra on a Single-Node Cluster
Container Orchestration : Docker Swarm vs Kubernetes vs Apache Mesos
OpenStack install on Ubuntu 16.04 server - DevStack
AWS EC2 Container Service (ECS) & EC2 Container Registry (ECR) | Docker Registry
CI/CD with CircleCI - Heroku deploy
Introduction to Terraform with AWS elb & nginx
Docker & Kubernetes
Kubernetes I - Running Kubernetes Locally via Minikube
Kubernetes II - kops on AWS
Kubernetes III - kubeadm on AWS
AWS : EKS (Elastic Container Service for Kubernetes)
CI/CD Github actions
CI/CD Gitlab
DevOps / Sys Admin Q & A
(1A) - Linux Commands
(1B) - Linux Commands
(2) - Networks
(2B) - Networks
(3) - Linux Systems
(4) - Scripting (Ruby/Shell)
(5) - Configuration Management
(6) - AWS VPC setup (public/private subnets with NAT)
(6B) - AWS VPC Peering
(7) - Web server
(8) - Database
(9) - Linux System / Application Monitoring, Performance Tuning, Profiling Methods & Tools
(10) - Trouble Shooting: Load, Throughput, Response time and Leaks
(11) - SSH key pairs, SSL Certificate, and SSL Handshake
(12) - Why is the database slow?
(13) - Is my web site down?
(14) - Is my server down?
(15) - Why is the server sluggish?
(16A) - Serving multiple domains using Virtual Hosts - Apache
(16B) - Serving multiple domains using server block - Nginx
(16C) - Reverse proxy servers and load balancers - Nginx
(17) - Linux startup process
(18) - phpMyAdmin with Nginx virtual host as a subdomain
(19) - How to SSH login without password?
(20) - Log Rotation
(21) - Monitoring Metrics
(22) - lsof
(23) - Wireshark introduction
(24) - User account management
(25) - Domain Name System (DNS)
(26) - NGINX SSL/TLS, Caching, and Session
(27) - Troubleshooting 5xx server errors
(28) - Linux Systemd: journalctl
(29) - Linux Systemd: FirewallD
(30) - Linux: SELinux
(31) - Linux: Samba
(0) - Linux Sys Admin's Day to Day tasks
Jenkins
Install
Configuration - Manage Jenkins - security setup
Adding job and build
Scheduling jobs
Managing_plugins
Git/GitHub plugins, SSH keys configuration, and Fork/Clone
JDK & Maven setup
Build configuration for GitHub Java application with Maven
Build Action for GitHub Java application with Maven - Console Output, Updating Maven
Commit to changes to GitHub & new test results - Build Failure
Commit to changes to GitHub & new test results - Successful Build
Adding code coverage and metrics
Jenkins on EC2 - creating an EC2 account, ssh to EC2, and install Apache server
Jenkins on EC2 - setting up Jenkins account, plugins, and Configure System (JAVA_HOME, MAVEN_HOME, notification email)
Jenkins on EC2 - Creating a Maven project
Jenkins on EC2 - Configuring GitHub Hook and Notification service to Jenkins server for any changes to the repository
Jenkins on EC2 - Line Coverage with JaCoCo plugin
Setting up Master and Slave nodes
Jenkins Build Pipeline & Dependency Graph Plugins
Jenkins Build Flow Plugin
Pipeline Jenkinsfile with Classic / Blue Ocean
Jenkins Setting up Slave nodes on AWS
Jenkins Q & A
Puppet
Puppet with Amazon AWS I - Puppet accounts
Puppet with Amazon AWS II (ssh & puppetmaster/puppet install)
Puppet with Amazon AWS III - Puppet running Hello World
Puppet Code Basics - Terminology
Puppet with Amazon AWS on CentOS 7 (I) - Master setup on EC2
Puppet with Amazon AWS on CentOS 7 (II) - Configuring a Puppet Master Server with Passenger and Apache
Puppet master /agent ubuntu 14.04 install on EC2 nodes
Puppet master post install tasks - master's names and certificates setup,
Puppet agent post install tasks - configure agent, hostnames, and sign request
EC2 Puppet master/agent basic tasks - main manifest with a file resource/module and immediate execution on an agent node
Setting up puppet master and agent with simple scripts on EC2 / remote install from desktop
EC2 Puppet - Install lamp with a manifest ('puppet apply')
EC2 Puppet - Install lamp with a module
Puppet variable scope
Puppet packages, services, and files
Puppet packages, services, and files II with nginx Puppet templates
Puppet creating and managing user accounts with SSH access
Puppet Locking user accounts & deploying sudoers file
Puppet exec resource
Puppet classes and modules
Puppet Forge modules
Puppet Express
Puppet Express 2
Puppet 4 : Changes
Puppet --configprint
Puppet with Docker
Puppet 6.0.2 install on Ubuntu 18.04
Chef
What is Chef?
Chef install on Ubuntu 14.04 - Local Workstation via omnibus installer
Setting up Hosted Chef server
VirtualBox via Vagrant with Chef client provision
Creating and using cookbooks on a VirtualBox node
Chef server install on Ubuntu 14.04
Chef workstation setup on EC2 Ubuntu 14.04
Chef Client Node - Knife Bootstrapping a node on EC2 ubuntu 14.04
Docker & K8s
Docker install on Amazon Linux AMI
Docker install on EC2 Ubuntu 14.04
Docker container vs Virtual Machine
Docker install on Ubuntu 14.04
Docker Hello World Application
Nginx image - share/copy files, Dockerfile
Working with Docker images : brief introduction
Docker image and container via docker commands (search, pull, run, ps, restart, attach, and rm)
More on docker run command (docker run -it, docker run --rm, etc.)
Docker Networks - Bridge Driver Network
Docker Persistent Storage
File sharing between host and container (docker run -d -p -v)
Linking containers and volume for datastore
Dockerfile - Build Docker images automatically I - FROM, MAINTAINER, and build context
Dockerfile - Build Docker images automatically II - revisiting FROM, MAINTAINER, build context, and caching
Dockerfile - Build Docker images automatically III - RUN
Dockerfile - Build Docker images automatically IV - CMD
Dockerfile - Build Docker images automatically V - WORKDIR, ENV, ADD, and ENTRYPOINT
Docker - Apache Tomcat
Docker - NodeJS
Docker - NodeJS with hostname
Docker Compose - NodeJS with MongoDB
Docker - Prometheus and Grafana with Docker-compose
Docker - StatsD/Graphite/Grafana
Docker - Deploying a Java EE JBoss/WildFly Application on AWS Elastic Beanstalk Using Docker Containers
Docker : NodeJS with GCP Kubernetes Engine
Docker : Jenkins Multibranch Pipeline with Jenkinsfile and Github
Docker : Jenkins Master and Slave
Docker - ELK : ElasticSearch, Logstash, and Kibana
Docker - ELK 7.6 : Elasticsearch on Centos 7 Docker - ELK 7.6 : Filebeat on Centos 7
Docker - ELK 7.6 : Logstash on Centos 7
Docker - ELK 7.6 : Kibana on Centos 7 Part 1
Docker - ELK 7.6 : Kibana on Centos 7 Part 2
Docker - ELK 7.6 : Elastic Stack with Docker Compose
Docker - Deploy Elastic Cloud on Kubernetes (ECK) via Elasticsearch operator on minikube
Docker - Deploy Elastic Stack via Helm on minikube
Docker Compose - A gentle introduction with WordPress
Docker Compose - MySQL
MEAN Stack app on Docker containers : micro services
Docker Compose - Hashicorp's Vault and Consul Part A (install vault, unsealing, static secrets, and policies)
Docker Compose - Hashicorp's Vault and Consul Part B (EaaS, dynamic secrets, leases, and revocation)
Docker Compose - Hashicorp's Vault and Consul Part C (Consul)
Docker Compose with two containers - Flask REST API service container and an Apache server container
Docker compose : Nginx reverse proxy with multiple containers
Docker compose : Nginx reverse proxy with multiple containers
Docker & Kubernetes : Envoy - Getting started
Docker & Kubernetes : Envoy - Front Proxy
Docker & Kubernetes : Ambassador - Envoy API Gateway on Kubernetes
Docker Packer
Docker Cheat Sheet
Docker Q & A
Kubernetes Q & A - Part I
Kubernetes Q & A - Part II
Docker - Run a React app in a docker
Docker - Run a React app in a docker II (snapshot app with nginx)
Docker - NodeJS and MySQL app with React in a docker
Docker - Step by Step NodeJS and MySQL app with React - I
Installing LAMP via puppet on Docker
Docker install via Puppet
Nginx Docker install via Ansible
Apache Hadoop CDH 5.8 Install with QuickStarts Docker
Docker - Deploying Flask app to ECS
Docker Compose - Deploying WordPress to AWS
Docker - WordPress Deploy to ECS with Docker-Compose (ECS-CLI EC2 type)
Docker - ECS Fargate
Docker - AWS ECS service discovery with Flask and Redis
Docker & Kubernetes: minikube version: v1.31.2, 2023
Docker & Kubernetes 1 : minikube
Docker & Kubernetes 2 : minikube Django with Postgres - persistent volume
Docker & Kubernetes 3 : minikube Django with Redis and Celery
Docker & Kubernetes 4 : Django with RDS via AWS Kops
Docker & Kubernetes : Kops on AWS
Docker & Kubernetes : Ingress controller on AWS with Kops
Docker & Kubernetes : HashiCorp's Vault and Consul on minikube
Docker & Kubernetes : HashiCorp's Vault and Consul - Auto-unseal using Transit Secrets Engine
Docker & Kubernetes : Persistent Volumes & Persistent Volumes Claims - hostPath and annotations
Docker & Kubernetes : Persistent Volumes - Dynamic volume provisioning
Docker & Kubernetes : DaemonSet
Docker & Kubernetes : Secrets
Docker & Kubernetes : kubectl command
Docker & Kubernetes : Assign a Kubernetes Pod to a particular node in a Kubernetes cluster
Docker & Kubernetes : Configure a Pod to Use a ConfigMap
AWS : EKS (Elastic Container Service for Kubernetes)
Docker & Kubernetes : Run a React app in a minikube
Docker & Kubernetes : Minikube install on AWS EC2
Docker & Kubernetes : Cassandra with a StatefulSet
Docker & Kubernetes : Terraform and AWS EKS
Docker & Kubernetes : Pods and Service definitions
Docker & Kubernetes : Headless service and discovering pods
Docker & Kubernetes : Service IP and the Service Type
Docker & Kubernetes : Kubernetes DNS with Pods and Services
Docker & Kubernetes - Scaling and Updating application
Docker & Kubernetes : Horizontal pod autoscaler on minikubes
Docker & Kubernetes : NodePort vs LoadBalancer vs Ingress
Docker & Kubernetes : Load Testing with Locust on GCP Kubernetes
Docker & Kubernetes : From a monolithic app to micro services on GCP Kubernetes
Docker & Kubernetes : Rolling updates
Docker & Kubernetes : Deployments to GKE (Rolling update, Canary and Blue-green deployments)
Docker & Kubernetes : Slack Chat Bot with NodeJS on GCP Kubernetes
Docker & Kubernetes : Continuous Delivery with Jenkins Multibranch Pipeline for Dev, Canary, and Production Environments on GCP Kubernetes
Docker & Kubernetes - MongoDB with StatefulSets on GCP Kubernetes Engine
Docker & Kubernetes : Nginx Ingress Controller on minikube
Docker & Kubernetes : Setting up Ingress with NGINX Controller on Minikube (Mac)
Docker & Kubernetes : Nginx Ingress Controller for Dashboard service on Minikube
Docker & Kubernetes : Nginx Ingress Controller on GCP Kubernetes
Docker & Kubernetes : Kubernetes Ingress with AWS ALB Ingress Controller in EKS
Docker & Kubernetes : MongoDB / MongoExpress on Minikube
Docker & Kubernetes : Setting up a private cluster on GCP Kubernetes
Docker & Kubernetes : Kubernetes Namespaces (default, kube-public, kube-system) and switching namespaces (kubens)
Docker & Kubernetes : StatefulSets on minikube
Docker & Kubernetes : StatefulSets on minikube
Docker & Kubernetes : RBAC
Docker & Kubernetes Service Account, RBAC, and IAM
Docker & Kubernetes - Kubernetes Service Account, RBAC, IAM with EKS ALB, Part 1
Docker & Kubernetes : Helm Chart
Docker & Kubernetes : My first Helm deploy
Docker & Kubernetes : Readiness and Liveness Probes
Docker & Kubernetes : Helm chart repository with Github pages
Docker & Kubernetes : Deploying WordPress and MariaDB with Ingress to Minikube using Helm Chart
Docker & Kubernetes : Deploying WordPress and MariaDB to AWS using Helm 2 Chart
Docker & Kubernetes : Deploying WordPress and MariaDB to AWS using Helm 3 Chart
Docker & Kubernetes : Helm Chart for Node/Express and MySQL with Ingress
Docker & Kubernetes : Docker_Helm_Chart_Node_Expess_MySQL_Ingress.php
Docker & Kubernetes: Deploy Prometheus and Grafana using Helm and Prometheus Operator - Monitoring Kubernetes node resources out of the box
Docker & Kubernetes : Deploy Prometheus and Grafana using kube-prometheus-stack Helm Chart
Docker & Kubernetes : Istio (service mesh) sidecar proxy on GCP Kubernetes
Docker & Kubernetes : Istio on EKS
Docker & Kubernetes : Istio on Minikube with AWS EC2 for Bookinfo Application
Docker & Kubernetes : Deploying .NET Core app to Kubernetes Engine and configuring its traffic managed by Istio (Part I)
Docker & Kubernetes : Deploying .NET Core app to Kubernetes Engine and configuring its traffic managed by Istio (Part II - Prometheus, Grafana, pin a service, split traffic, and inject faults)
Docker & Kubernetes : Helm Package Manager with MySQL on GCP Kubernetes Engine
Docker & Kubernetes : Deploying Memcached on Kubernetes Engine
Docker & Kubernetes : EKS Control Plane (API server) Metrics with Prometheus
Docker & Kubernetes : Spinnaker on EKS with Halyard
Docker & Kubernetes : Continuous Delivery Pipelines with Spinnaker and Kubernetes Engine
Docker & Kubernetes: Multi-node Local Kubernetes cluster - Kubeadm-dind(docker-in-docker)
Docker & Kubernetes: Multi-node Local Kubernetes cluster - Kubeadm-kind(k8s-in-docker)
Docker & Kubernetes : nodeSelector, nodeAffinity, taints/tolerations, pod affinity and anti-affinity - Assigning Pods to Nodes
Docker & Kubernetes : Jenkins-X on EKS
Docker & Kubernetes : ArgoCD App of Apps with Heml on Kubernetes
Docker & Kubernetes : ArgoCD on Kubernetes cluster
Docker & Kubernetes : GitOps with ArgoCD for Continuous Delivery to Kubernetes clusters (minikube) - guestbook
Vagrant
VirtualBox & Vagrant install on Ubuntu 14.04
Creating a VirtualBox using Vagrant
Provisioning
Networking - Port Forwarding
Vagrant Share
Vagrant Rebuild & Teardown
Vagrant & Ansible
AWS (Amazon Web Services)
AWS : EKS (Elastic Container Service for Kubernetes)
AWS : Creating a snapshot (cloning an image)
AWS : Attaching Amazon EBS volume to an instance
AWS : Adding swap space to an attached volume via mkswap and swapon
AWS : Creating an EC2 instance and attaching Amazon EBS volume to the instance using Python boto module with User data
AWS : Creating an instance to a new region by copying an AMI
AWS : S3 (Simple Storage Service) 1
AWS : S3 (Simple Storage Service) 2 - Creating and Deleting a Bucket
AWS : S3 (Simple Storage Service) 3 - Bucket Versioning
AWS : S3 (Simple Storage Service) 4 - Uploading a large file
AWS : S3 (Simple Storage Service) 5 - Uploading folders/files recursively
AWS : S3 (Simple Storage Service) 6 - Bucket Policy for File/Folder View/Download
AWS : S3 (Simple Storage Service) 7 - How to Copy or Move Objects from one region to another
AWS : S3 (Simple Storage Service) 8 - Archiving S3 Data to Glacier
AWS : Creating a CloudFront distribution with an Amazon S3 origin
AWS : Creating VPC with CloudFormation
WAF (Web Application Firewall) with preconfigured CloudFormation template and Web ACL for CloudFront distribution
AWS : CloudWatch & Logs with Lambda Function / S3
AWS : Lambda Serverless Computing with EC2, CloudWatch Alarm, SNS
AWS : Lambda and SNS - cross account
AWS : CLI (Command Line Interface)
AWS : CLI (ECS with ALB & autoscaling)
AWS : ECS with cloudformation and json task definition
AWS : AWS Application Load Balancer (ALB) and ECS with Flask app
AWS : Load Balancing with HAProxy (High Availability Proxy)
AWS : VirtualBox on EC2
AWS : NTP setup on EC2
AWS: jq with AWS
AWS : AWS & OpenSSL : Creating / Installing a Server SSL Certificate
AWS : OpenVPN Access Server 2 Install
AWS : VPC (Virtual Private Cloud) 1 - netmask, subnets, default gateway, and CIDR
AWS : VPC (Virtual Private Cloud) 2 - VPC Wizard
AWS : VPC (Virtual Private Cloud) 3 - VPC Wizard with NAT
AWS : DevOps / Sys Admin Q & A (VI) - AWS VPC setup (public/private subnets with NAT)
AWS : OpenVPN Protocols : PPTP, L2TP/IPsec, and OpenVPN
AWS : Autoscaling group (ASG)
AWS : Setting up Autoscaling Alarms and Notifications via CLI and Cloudformation
AWS : Adding a SSH User Account on Linux Instance
AWS : Windows Servers - Remote Desktop Connections using RDP
AWS : Scheduled stopping and starting an instance - python & cron
AWS : Detecting stopped instance and sending an alert email using Mandrill smtp
AWS : Elastic Beanstalk with NodeJS
AWS : Elastic Beanstalk Inplace/Rolling Blue/Green Deploy
AWS : Identity and Access Management (IAM) Roles for Amazon EC2
AWS : Identity and Access Management (IAM) Policies, sts AssumeRole, and delegate access across AWS accounts
AWS : Identity and Access Management (IAM) sts assume role via aws cli2
AWS : Creating IAM Roles and associating them with EC2 Instances in CloudFormation
AWS Identity and Access Management (IAM) Roles, SSO(Single Sign On), SAML(Security Assertion Markup Language), IdP(identity provider), STS(Security Token Service), and ADFS(Active Directory Federation Services)
AWS : Amazon Route 53
AWS : Amazon Route 53 - DNS (Domain Name Server) setup
AWS : Amazon Route 53 - subdomain setup and virtual host on Nginx
AWS Amazon Route 53 : Private Hosted Zone
AWS : SNS (Simple Notification Service) example with ELB and CloudWatch
AWS : Lambda with AWS CloudTrail
AWS : SQS (Simple Queue Service) with NodeJS and AWS SDK
AWS : Redshift data warehouse
AWS : CloudFormation - templates, change sets, and CLI
AWS : CloudFormation Bootstrap UserData/Metadata
AWS : CloudFormation - Creating an ASG with rolling update
AWS : Cloudformation Cross-stack reference
AWS : OpsWorks
AWS : Network Load Balancer (NLB) with Autoscaling group (ASG)
AWS CodeDeploy : Deploy an Application from GitHub
AWS EC2 Container Service (ECS)
AWS EC2 Container Service (ECS) II
AWS Hello World Lambda Function
AWS Lambda Function Q & A
AWS Node.js Lambda Function & API Gateway
AWS API Gateway endpoint invoking Lambda function
AWS API Gateway invoking Lambda function with Terraform
AWS API Gateway invoking Lambda function with Terraform - Lambda Container
Amazon Kinesis Streams
Kinesis Data Firehose with Lambda and ElasticSearch
Amazon DynamoDB
Amazon DynamoDB with Lambda and CloudWatch
Loading DynamoDB stream to AWS Elasticsearch service with Lambda
Amazon ML (Machine Learning)
Simple Systems Manager (SSM)
AWS : RDS Connecting to a DB Instance Running the SQL Server Database Engine
AWS : RDS Importing and Exporting SQL Server Data
AWS : RDS PostgreSQL & pgAdmin III
AWS : RDS PostgreSQL 2 - Creating/Deleting a Table
AWS : MySQL Replication : Master-slave
AWS : MySQL backup & restore
AWS RDS : Cross-Region Read Replicas for MySQL and Snapshots for PostgreSQL
AWS : Restoring Postgres on EC2 instance from S3 backup
AWS : Q & A
AWS : Security
AWS : Security groups vs. network ACLs
AWS : Scaling-Up
AWS : Networking
AWS : Single Sign-on (SSO) with Okta
AWS : JIT (Just-in-Time) with Okta