Prim's spanning tree algorithm
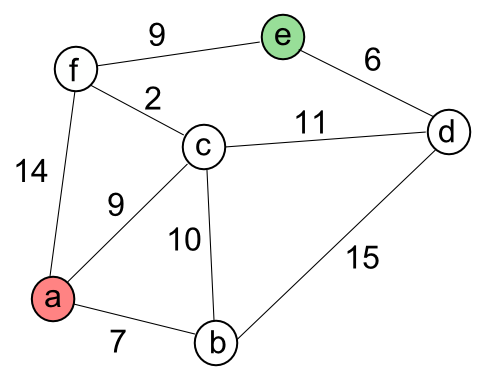
We want to find a minimum spanning tree for a connected weighted undirected graph. This means it finds a subset of the edges that forms a tree that includes every vertex, where the total weight of all the edges in the tree is minimized. So, for the targets 'd', 'e', and 'f', the it should construct the following tree (red and blue)
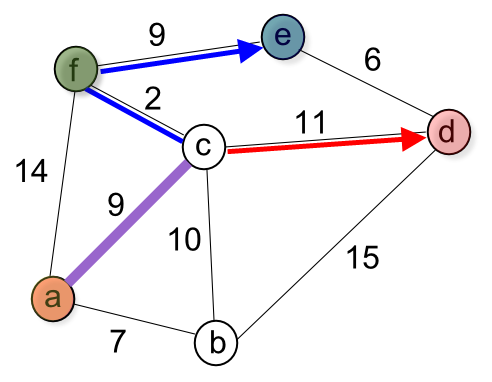
We can use Dijkstra's algorithm (see Dijkstra's shortest path algorithm) to construct Prim's spanning tree. Dijkstra's algorithm is an iterative algorithm that provides us with the shortest path from one particular starting node (a in our case) to all other nodes in the graph. Again this is similar to the results of a breadth first search.
To keep track of the total cost from the start node to each destination we will make use of the dist instance variable in the Vertex class. The dist instance variable will contain the current total weight of the smallest weight path from the start to the vertex in question. The algorithm iterates once for every vertex in the graph; however, the order that we iterate over the vertices is controlled by a priority queue (actually, in the code, I used heapq).
The value that is used to determine the order of the objects in the priority queue is dist. When a vertex is first created dist is set to a very large number.
When the algorithm finishes the distances are set correctly as are the predecessor (previous in the code) links for each vertex in the graph.
In the code, we create two classes: Graph, which holds the master list of vertices, and Vertex, which represents each vertex in the graph (see Graph data structure).
The source file is Prims.py.
The function dijkstra() calculates the shortest path. The shortest() function constructs the shortest path starting from the target ('e') using predecessors.
import sys
class Vertex:
def __init__(self, node):
self.id = node
self.adjacent = {}
# Set distance to infinity for all nodes
self.distance = sys.maxint
# Mark all nodes unvisited
self.visited = False
# Predecessor
self.previous = None
def add_neighbor(self, neighbor, weight=0):
self.adjacent[neighbor] = weight
def get_connections(self):
return self.adjacent.keys()
def get_id(self):
return self.id
def get_weight(self, neighbor):
return self.adjacent[neighbor]
def set_distance(self, dist):
self.distance = dist
def get_distance(self):
return self.distance
def set_previous(self, prev):
self.previous = prev
def set_visited(self):
self.visited = True
def __str__(self):
return str(self.id) + ' adjacent: ' + str([x.id for x in self.adjacent])
class Graph:
def __init__(self):
self.vert_dict = {}
self.num_vertices = 0
def __iter__(self):
return iter(self.vert_dict.values())
def add_vertex(self, node):
self.num_vertices = self.num_vertices + 1
new_vertex = Vertex(node)
self.vert_dict[node] = new_vertex
return new_vertex
def get_vertex(self, n):
if n in self.vert_dict:
return self.vert_dict[n]
else:
return None
def add_edge(self, frm, to, cost = 0):
if frm not in self.vert_dict:
self.add_vertex(frm)
if to not in self.vert_dict:
self.add_vertex(to)
self.vert_dict[frm].add_neighbor(self.vert_dict[to], cost)
self.vert_dict[to].add_neighbor(self.vert_dict[frm], cost)
def get_vertices(self):
return self.vert_dict.keys()
def set_previous(self, current):
self.previous = current
def get_previous(self, current):
return self.previous
def shortest(v, path):
''' make shortest path from v.previous'''
if v.previous:
path.append(v.previous.get_id())
shortest(v.previous, path)
return
import heapq
def dijkstra(aGraph, start):
print '''Dijkstra's shortest path'''
# Set the distance for the start node to zero
start.set_distance(0)
# Put tuple pair into the priority queue
unvisited_queue = [(v.get_distance(),v) for v in aGraph]
heapq.heapify(unvisited_queue)
while len(unvisited_queue):
# Pops a vertex with the smallest distance
uv = heapq.heappop(unvisited_queue)
current = uv[1]
current.set_visited()
#for next in v.adjacent:
for next in current.adjacent:
# if visited, skip
if next.visited:
continue
new_dist = current.get_distance() + current.get_weight(next)
if new_dist < next.get_distance():
next.set_distance(new_dist)
next.set_previous(current)
print 'updated : current = %s next = %s new_dist = %s' \
%(current.get_id(), next.get_id(), next.get_distance())
else:
print 'not updated : current = %s next = %s new_dist = %s' \
%(current.get_id(), next.get_id(), next.get_distance())
# Rebuild heap
# 1. Pop every item
while len(unvisited_queue):
heapq.heappop(unvisited_queue)
# 2. Put all vertices not visited into the queue
unvisited_queue = [(v.get_distance(),v) for v in aGraph if not v.visited]
heapq.heapify(unvisited_queue)
if __name__ == '__main__':
g = Graph()
g.add_vertex('a')
g.add_vertex('b')
g.add_vertex('c')
g.add_vertex('d')
g.add_vertex('e')
g.add_vertex('f')
g.add_edge('a', 'b', 7)
g.add_edge('a', 'c', 9)
g.add_edge('a', 'f', 14)
g.add_edge('b', 'c', 10)
g.add_edge('b', 'd', 15)
g.add_edge('c', 'd', 11)
g.add_edge('c', 'f', 2)
g.add_edge('d', 'e', 6)
g.add_edge('e', 'f', 9)
print 'Graph data:'
for v in g:
for w in v.get_connections():
vid = v.get_id()
wid = w.get_id()
print '( %s , %s, %3d)' % ( vid, wid, v.get_weight(w))
dijkstra(g, g.get_vertex('a'))
for t in ['d','e','f']:
target = g.get_vertex(t)
path = [t]
shortest(target, path)
print 'The shortest path for %s : %s' %(t, path[::-1])
Output:
Graph data: ( a , c, 9) ( a , b, 7) ( a , f, 14) ( c , b, 10) ( c , d, 11) ( c , f, 2) ( c , a, 9) ( b , c, 10) ( b , d, 15) ( b , a, 7) ( e , d, 6) ( e , f, 9) ( d , c, 11) ( d , e, 6) ( d , b, 15) ( f , c, 2) ( f , e, 9) ( f , a, 14) Dijkstra's shortest path updated : current = a next = c new_dist = 9 updated : current = a next = b new_dist = 7 updated : current = a next = f new_dist = 14 not updated : current = b next = c new_dist = 9 updated : current = b next = d new_dist = 22 updated : current = c next = d new_dist = 20 updated : current = c next = f new_dist = 11 updated : current = f next = e new_dist = 20 not updated : current = d next = e new_dist = 20 The shortest path for d : ['a', 'c', 'd'] The shortest path for e : ['a', 'c', 'f', 'e'] The shortest path for f : ['a', 'c', 'f']
The steps to calculates the path are:
- Assign to every node a tentative distance value: set it to zero for our initial node and to infinity for all other nodes. Actually, initialization is done in the Vertex constructor:
self.distance = sys.maxint
For the starting node, initialization is done in dijkstra()
print '''Dijkstra's shortest path''' # Set the distance for the start node to zero start.set_distance(0)
- Mark all nodes unvisited. This is also done in the Vertex constructor:
self.visited = False
- Set the initial node as current. Create a list of the unvisited nodes called the unvisited list consisting of all the nodes. We do it using tuple pair, (distance, v)
def dijkstra(aGraph, start, target): print '''Dijkstra's shortest path''' # Set the distance for the start node to zero start.set_distance(0) # Put tuple pair into the priority queue unvisited_queue = [(v.get_distance(),v) for v in aGraph] heapq.heapify(unvisited_queue) -
For the current node, consider all of its unvisited neighbors and calculate their tentative distances. Compare the newly calculated tentative distance to the current assigned value and assign the smaller one. For example, if the current node A is marked with a distance of 6, and the edge connecting it with a neighbor B has length 2, then the distance to B (through A) will be 6 + 2 = 8. If B was previously marked with a distance greater than 8 then change it to 8. Otherwise, keep the current value.
while len(unvisited_queue): # Pops a vertex with the smallest distance uv = heapq.heappop(unvisited_queue) current = uv[1] current.set_visited() #for next in v.adjacent: for next in current.adjacent: # if visited, skip if next.visited: continue new_dist = current.get_distance() + current.get_weight(next) if new_dist < next.get_distance(): next.set_distance(new_dist) next.set_previous(current) print 'updated : current = %s next = %s new_dist = %s' \ %(current.get_id(), next.get_id(), next.get_distance()) else: print 'not updated : current = %s next = %s new_dist = %s' \ %(current.get_id(), next.get_id(), next.get_distance()) - When we are done considering all of the neighbors of the current node, mark the current node as visited and remove it from the unvisited set.
while len(unvisited_queue): # Pops a vertex with the smallest distance uv = heapq.heappop(unvisited_queue) current = uv[1] current.set_visited() ... # Rebuild heap # 1. Pop every item while len(unvisited_queue): heapq.heappop(unvisited_queue) # 2. Put all vertices not visited into the queue unvisited_queue = [(v.get_distance(),v) for v in aGraph if not v.visited] heapq.heapify(unvisited_queue)For each new node visit, we rebuild the heap: pop all items, refill the unvisited_queue, and then heapify it.
- A visited node will never be checked again. #for next in v.adjacent: for next in current.adjacent: # if visited, skip if next.visited: continue
- If there is no unvisited node, the algorithm has finished. Otherwise, we go back to step 4.
- Gather predecessors starting from the target node ('e'). In the code, it's done in shortest() function.
def shortest(v, path): ''' make shortest path from v.previous''' if v.previous: path.append(v.previous.get_id()) shortest(v.previous, path) return
Python tutorial
Python Home
Introduction
Running Python Programs (os, sys, import)
Modules and IDLE (Import, Reload, exec)
Object Types - Numbers, Strings, and None
Strings - Escape Sequence, Raw String, and Slicing
Strings - Methods
Formatting Strings - expressions and method calls
Files and os.path
Traversing directories recursively
Subprocess Module
Regular Expressions with Python
Regular Expressions Cheat Sheet
Object Types - Lists
Object Types - Dictionaries and Tuples
Functions def, *args, **kargs
Functions lambda
Built-in Functions
map, filter, and reduce
Decorators
List Comprehension
Sets (union/intersection) and itertools - Jaccard coefficient and shingling to check plagiarism
Hashing (Hash tables and hashlib)
Dictionary Comprehension with zip
The yield keyword
Generator Functions and Expressions
generator.send() method
Iterators
Classes and Instances (__init__, __call__, etc.)
if__name__ == '__main__'
argparse
Exceptions
@static method vs class method
Private attributes and private methods
bits, bytes, bitstring, and constBitStream
json.dump(s) and json.load(s)
Python Object Serialization - pickle and json
Python Object Serialization - yaml and json
Priority queue and heap queue data structure
Graph data structure
Dijkstra's shortest path algorithm
Prim's spanning tree algorithm
Closure
Functional programming in Python
Remote running a local file using ssh
SQLite 3 - A. Connecting to DB, create/drop table, and insert data into a table
SQLite 3 - B. Selecting, updating and deleting data
MongoDB with PyMongo I - Installing MongoDB ...
Python HTTP Web Services - urllib, httplib2
Web scraping with Selenium for checking domain availability
REST API : Http Requests for Humans with Flask
Blog app with Tornado
Multithreading ...
Python Network Programming I - Basic Server / Client : A Basics
Python Network Programming I - Basic Server / Client : B File Transfer
Python Network Programming II - Chat Server / Client
Python Network Programming III - Echo Server using socketserver network framework
Python Network Programming IV - Asynchronous Request Handling : ThreadingMixIn and ForkingMixIn
Python Coding Questions I
Python Coding Questions II
Python Coding Questions III
Python Coding Questions IV
Python Coding Questions V
Python Coding Questions VI
Python Coding Questions VII
Python Coding Questions VIII
Image processing with Python image library Pillow
Python and C++ with SIP
PyDev with Eclipse
Matplotlib
Redis with Python
NumPy array basics A
NumPy Matrix and Linear Algebra
Pandas with NumPy and Matplotlib
Celluar Automata
Batch gradient descent algorithm
Longest Common Substring Algorithm
Python Unit Test - TDD using unittest.TestCase class
Simple tool - Google page ranking by keywords
Google App Hello World
Google App webapp2 and WSGI
Uploading Google App Hello World
Python 2 vs Python 3
virtualenv and virtualenvwrapper
Uploading a big file to AWS S3 using boto module
Scheduled stopping and starting an AWS instance
Cloudera CDH5 - Scheduled stopping and starting services
Removing Cloud Files - Rackspace API with curl and subprocess
Checking if a process is running/hanging and stop/run a scheduled task on Windows
Apache Spark 1.3 with PySpark (Spark Python API) Shell
Apache Spark 1.2 Streaming
bottle 0.12.7 - Fast and simple WSGI-micro framework for small web-applications ...
Flask app with Apache WSGI on Ubuntu14/CentOS7 ...
Fabric - streamlining the use of SSH for application deployment
Ansible Quick Preview - Setting up web servers with Nginx, configure enviroments, and deploy an App
Neural Networks with backpropagation for XOR using one hidden layer
NLP - NLTK (Natural Language Toolkit) ...
RabbitMQ(Message broker server) and Celery(Task queue) ...
OpenCV3 and Matplotlib ...
Simple tool - Concatenating slides using FFmpeg ...
iPython - Signal Processing with NumPy
iPython and Jupyter - Install Jupyter, iPython Notebook, drawing with Matplotlib, and publishing it to Github
iPython and Jupyter Notebook with Embedded D3.js
Downloading YouTube videos using youtube-dl embedded with Python
Machine Learning : scikit-learn ...
Django 1.6/1.8 Web Framework ...
Ph.D. / Golden Gate Ave, San Francisco / Seoul National Univ / Carnegie Mellon / UC Berkeley / DevOps / Deep Learning / Visualization