Apache Spark Streaming
Here is an interesting article - Beyond Hadoop: The streaming future of big data.
Cloudera's Dug Cutting:
It wasn't as though Hadoop was architected around batch because we felt batch was best. Rather, batch, MapReduce in particular, was a natural first step because it was relatively easy to implement and provided great value. Before Hadoop, there was no way to store and process petabytes on commodity hardware using open source software. Hadoop's MapReduce provided folks with a big step in capability.
Zoomdata CEO, Justin Langseth
Real-time data is obviously best handled as a stream. But it's possible to stream historical data as well, just as your DVR can stream "Gone with the Wind," or last week's "American Idol" to your TV. This distinction is important, as we at Zoomdata believe that analyzing data as a stream adds huge scalability and flexibility benefits, regardless of if the data is real-time or historical.
Cutting again:
I suspect that major additions to the stack like Spark will become less frequent, so that over time, we'll standardize on a set of tools that provide the range of capabilities that most folks demand from their big data applications. Hadoop ignited a Cambrian explosion of related projects, but we'll likely enter a time of more normal evolution, as use of these technologies spreads through industries.
This chapter borrowed the materials mostly from Spark Streaming Programming Guide.
A Spark Streaming application is very similar to a Spark application. It consists of a driver program that runs the user's main function and continuous executes various parallel operations on input streams of data. The main abstraction Spark Streaming provides is a discretized stream (DStream), which is a continuous sequence of RDDs (distributed collections of elements) representing a continuous stream of data. DStreams can be created from live incoming data (such as data from a socket, Kafka, etc.) or can be generated by transforming existing DStreams using parallel operators like map, reduce, and window.
The basic processing model is as follows:
- While a Spark Streaming driver program is running, the system receives data from various sources and and divides it into batches. Each batch of data is treated as an RDD, that is, an immutable parallel collection of data. These input RDDs are saved in memory and replicated to two nodes for fault-tolerance. This sequence of RDDs is collectively called an InputDStream.
- Data received by InputDStreams are processed using DStream operations. Since all data is represented as RDDs and all DStream operations as RDD operations, data is automatically recovered in the event of node failures.
Spark Streaming is an extension of the core Spark API that allows enables high-throughput, fault-tolerant stream processing of live data streams. Data can be ingested from many sources like Kafka, Flume, Twitter, ZeroMQ or plain old TCP sockets and be processed using complex algorithms expressed with high-level functions like map, reduce, join and window. Finally, processed data can be pushed out to filesystems, databases, and live dashboards. In fact, you can apply Spark's in-built machine learning algorithms, and graph processing algorithms on data streams.

Internally, it works as follows. Spark Streaming receives live input data streams and divides the data into batches, which are then processed by the Spark engine to generate the final stream of results in batches.

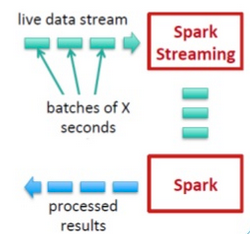
Picture source: Apache Spark.
- Run a streaming computation as a series of small batch jobs.
- Chop up the live stream into batches of X seconds.
- Spark treats each batch of data as RDDs and processes them using RDD operations.
- The processed results of the RDD operations are returned in batches.
Spark Streaming provides a high-level abstraction called discretized stream or DStream, which represents a continuous stream of data. DStreams can be created either from input data stream from sources such as Kafka and Flume, or by applying high-level operations on other DStreams. Internally, a DStream is represented as a sequence of RDDs.
We need to set PYTHONPATH in ~/.bashrc:
export SPARK_HOME=/usr/lib/spark export PYTHONPATH=$SPARK_HOME/python export PYTHONPATH=$SPARK_HOME/python/build/:$PYTHONPATH
In this section, we want to count the number of words in text data received from a data server listening on a TCP socket.
First, we import StreamingContext, which is the main entry point for all streaming functionality.
Here is the Python code (network_wordcount.py) we're going to use (note: in the GitHub the 1st argument for "SparkContext()" is missing, and we need it to make it work - check Spark streaming network_wordcount.py does not print result).
"""
Counts words in UTF8 encoded, '\n' delimited text received from the network every second.
Usage: network_wordcount.py <hostname> <port>
<hostname> and <port> describe the TCP server that Spark Streaming would connect to receive data.
To run this on your local machine, you need to first run a Netcat server
`$ nc -lk 9999`
and then run the example
`$ bin/spark-submit examples/src/main/python/streaming/network_wordcount.py localhost 9999`
"""
from __future__ import print_function
import sys
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
if __name__ == "__main__":
if len(sys.argv) != 3:
print("Usage: network_wordcount.py <hostname> <port>", file=sys.stderr)
exit(-1)
sc = SparkContext("local[2]", appName="PythonStreamingNetworkWordCount")
ssc = StreamingContext(sc, 1)
lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))
counts = lines.flatMap(lambda line: line.split(" "))\
.map(lambda word: (word, 1))\
.reduceByKey(lambda a, b: a+b)
counts.pprint()
ssc.start()
ssc.awaitTermination()
This section explains the Python code line by line:
from pyspark import SparkContext from pyspark.streaming import StreamingContext
Then, we create a local StreamingContext with two working threads and batch interval of 1 second:
sc = SparkContext("local[2]", "NetworkWordCount")
ssc = StreamingContext(sc, 1)
Using this context, we can create a DStream that represents streaming data from a TCP source, specified as hostname (e.g. localhost) and port (e.g. 9999):
lines = ssc.socketTextStream("localhost", 9999)
This lines DStream represents the stream of data that will be received from the data server. Each record in this DStream is a line of text. Next, we want to split the lines by space into words:
words = lines.flatMap(lambda line: line.split(" "))
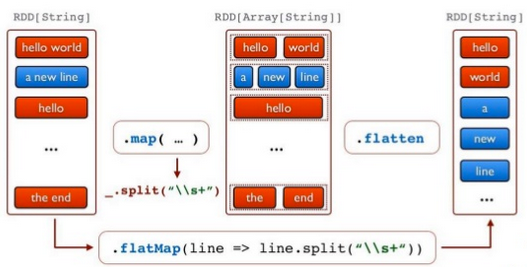
Picture source: Apache Spark.
The flatMap is a one-to-many DStream operation that creates a new DStream by generating multiple new records from each record in the source DStream. In this case, each line will be split into multiple words and the stream of words is represented as the words DStream. Next, we want to count these words:
pairs = words.map(lambda word: (word, 1))
The words DStream is further mapped (one-to-one transformation) to a DStream of (word, 1) pairs, which is then reduced to get the frequency of words in each batch of data:
wordCounts = pairs.reduceByKey(lambda a, b: a + b)
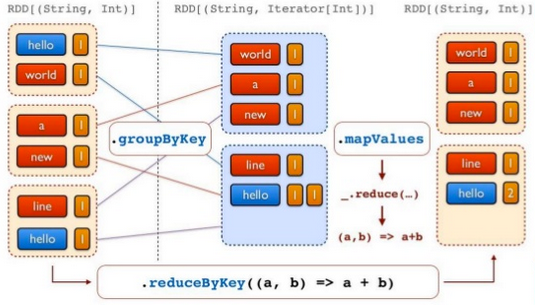
Picture source: Apache Spark.
Then, print the first ten elements of each RDD generated in this DStream to the console:
wordCounts.pprint()
Note that when these lines are executed, Spark Streaming only sets up the computation it will perform when it is started, and no real processing has started yet. To start the processing after all the transformations have been setup, we finally call :
ssc.start() ssc.awaitTermination()
We need to run Netcat(nc) as a data server. nc is the command which runs Netcat, a simple Unix utility that reads and writes data across network connections, using the TCP or UDP protocol. It is designed to be a reliable "back-end" tool that can be used directly or driven by other programs and scripts. At the same time, it is a feature-rich network debugging and exploration tool, since it can create almost any kind of connection wewould need and has several interesting built-in capabilities.
Let's listen for an incomming connection via a port 9999:
$ nc -lk 9999
The "-l" option is used to specify that nc should listen for an incoming connection. The "-k" option forces nc to stay listening for another connection after its current connection is completed. It is an error to use this option without the "-l" option.
Then, in a different terminal, we can start the Python code:
$ $SPARK_HOME/bin/spark-submit network_wordcount.py localhost 9999
Now add words in the console where we run nc:
Spark Streaming is an extension of the core Spark API that allows enables high-throughput, fault-tolerant stream processing of live data streams.
Then, we will get the output loke this:
-------------------------------------------
Time: 2015-05-03 13:06:41
-------------------------------------------
('stream', 1)
('extension', 1)
('is', 1)
('allows', 1)
('live', 1)
('fault-tolerant', 1)
('Spark', 2)
('data', 1)
('the', 1)
('core', 1)
...
Big Data & Hadoop Tutorials
Hadoop 2.6 - Installing on Ubuntu 14.04 (Single-Node Cluster)
Hadoop 2.6.5 - Installing on Ubuntu 16.04 (Single-Node Cluster)
Hadoop - Running MapReduce Job
Hadoop - Ecosystem
CDH5.3 Install on four EC2 instances (1 Name node and 3 Datanodes) using Cloudera Manager 5
CDH5 APIs
QuickStart VMs for CDH 5.3
QuickStart VMs for CDH 5.3 II - Testing with wordcount
QuickStart VMs for CDH 5.3 II - Hive DB query
Scheduled start and stop CDH services
CDH 5.8 Install with QuickStarts Docker
Zookeeper & Kafka Install
Zookeeper & Kafka - single node single broker
Zookeeper & Kafka - Single node and multiple brokers
OLTP vs OLAP
Apache Hadoop Tutorial I with CDH - Overview
Apache Hadoop Tutorial II with CDH - MapReduce Word Count
Apache Hadoop Tutorial III with CDH - MapReduce Word Count 2
Apache Hadoop (CDH 5) Hive Introduction
CDH5 - Hive Upgrade to 1.3 to from 1.2
Apache Hive 2.1.0 install on Ubuntu 16.04
Apache Hadoop : HBase in Pseudo-Distributed mode
Apache Hadoop : Creating HBase table with HBase shell and HUE
Apache Hadoop : Hue 3.11 install on Ubuntu 16.04
Apache Hadoop : Creating HBase table with Java API
Apache HBase : Map, Persistent, Sparse, Sorted, Distributed and Multidimensional
Apache Hadoop - Flume with CDH5: a single-node Flume deployment (telnet example)
Apache Hadoop (CDH 5) Flume with VirtualBox : syslog example via NettyAvroRpcClient
List of Apache Hadoop hdfs commands
Apache Hadoop : Creating Wordcount Java Project with Eclipse Part 1
Apache Hadoop : Creating Wordcount Java Project with Eclipse Part 2
Apache Hadoop : Creating Card Java Project with Eclipse using Cloudera VM UnoExample for CDH5 - local run
Apache Hadoop : Creating Wordcount Maven Project with Eclipse
Wordcount MapReduce with Oozie workflow with Hue browser - CDH 5.3 Hadoop cluster using VirtualBox and QuickStart VM
Spark 1.2 using VirtualBox and QuickStart VM - wordcount
Spark Programming Model : Resilient Distributed Dataset (RDD) with CDH
Apache Spark 1.2 with PySpark (Spark Python API) Wordcount using CDH5
Apache Spark 1.2 Streaming
Apache Spark 2.0.2 with PySpark (Spark Python API) Shell
Apache Spark 2.0.2 tutorial with PySpark : RDD
Apache Spark 2.0.0 tutorial with PySpark : Analyzing Neuroimaging Data with Thunder
Apache Spark Streaming with Kafka and Cassandra
Apache Drill with ZooKeeper - Install on Ubuntu 16.04
Apache Drill - Query File System, JSON, and Parquet
Apache Drill - HBase query
Apache Drill - Hive query
Apache Drill - MongoDB query
Ph.D. / Golden Gate Ave, San Francisco / Seoul National Univ / Carnegie Mellon / UC Berkeley / DevOps / Deep Learning / Visualization